
There is one thing in common between all B2B applications. Disregarding the way architecture of B2B application is designed, such an app represents a series of real-world workflows, oftentimes implicitly defined in different places of code.
The Challenge
The main problem of such “implicit” workflows is the mental effort required to keep everything in mind in order to properly maintain the system. Introducing changes to such a system is similar to navigating the minefield without a metal detector - very fun at the end if everything went fine, complete nightmare in the process.
💡
Interesting****fact: Example about the minefield is my personal experience, not a metaphor.
The Solution
Some business domains are complicated by their nature. There are no simple processes in logistics, healthcare or e-Commerce and many other industries. One eats elephants piece-by-piece. The reality is sometimes our elephants are made of other elephants.
Often to understand some complex business logic, we have to dig into documentation, diagrams and the code. Combining everything gives an approximate understanding of that logic. Then once this information is processed, software engineers hold everything in their heads. Blink of an eye, Slack message or a phone ringing effectively wipes out everything and the process starts over.
How to address such complexity? The answer is rather straightforward. If you can’t reduce the complexity, turn the implicit complexity into explicit. In other words, complicated workflows explicitly described in the system simplifies maintenance and allows to introduce changes into application in a predictable manner.
Let’s go through available tools to define and implement workflows, often used in B2B Software as a Service development.
Available Tools
There are plenty of workflow management solutions available both commercial and open-source. Depending on the workflow representation, such solutions can be split into two large groups:
- workflow management platforms with a code-based workflow definition
- workflow management platforms based on some kind of DSL(domain-specific language). Choosing between either of types depends on desired flexibility, team members maintain and defining workflows and performance requirements. Often, DSL-based workflow management solutions are built on top code-based workflow management solutions. Using DSL allows to further reduce the complexity of workflows by applying business-domain specific definitions and visual editing, while code-based workflows are often used for more flexibility, better performance and fine-grained control.
Apache Airflow
Apache Airflow is an open-source code-based workflow management system. It provides workflow management and monitoring capabilities. Airflow ecosystem is rich of powerful plugins for integrations with external systems called “providers”. The most popular use-case for Apache Airflow are ETL processes and ML ops.
AWS StepFunctions
Amazon Web Services provides a serverless orchestration platform called AWS Step Functions. Workflow declarations for AWS Step Functions are based on the DSL called “ASL” - Amazon States Language. ASL specification defines a workflow as a JSON object which consists states and transitions.
Orkes
Orkes is a commercial product based on the open-source Netflix Conductor (no longer supported). It has cloud-based and self-hosted versions and provides ability to create durable and failsafe workflows.
BPMN-based tools
Besides more general purpose workflow management systems, there is a subset of tools crafted specifically with the BPMN(Business Process Model and Notation) in mind. Such tools are DSL-based and use BPMN as a way to describe workflows.
Activity and jBPM are among them and rather famous in the Java world. Another bright player is Camunda, a cross-platform BPMN engine. The biggest benefit of such platforms is the notation language familiar to many business analysts and software engineers.
Temporal
Temporal introduces a separate concept for representing a business logic workflows called “Durable Execution”. This abstraction allows software engineers to design and implement resilient workflows which are suitable both for time-critical applications and long-running scenarios.
Temporal consists of two parts - language-specific libraries and temporal server runtime. The server part can be either open-source self-hosted or commercially-available cloud.
Selecting the right tool
Before proceeding with the criteria for tool selection, I’d like to bring up implicit vs explicit complexity topic one more time. In general, there are two patterns of interaction between components of complex systems - choreography and orchestration.
Choreography is a design pattern which implies the interaction between components is based purely on message exchange. While it may seem good due to s loose coupling of components, complex choreography-based systems are very difficult to maintain and debug.
Orchestration on the other hand requires a central entity to manage interaction between system components. It results in having a possible bottleneck and a single point of failure. The benefits though outweigh potential problems. Among such benefits are maintainability, easier debug and development processes, traceability.
There is no one-size-fits-all tool, and the tool should be picked based on the problem being solved. When creating a B2B Software-as-Service application, I always stick to a set of initial criteria with both speed of development and scalability in mind:
- For fully serverless AWS-based applications, Amazon Step Functions is hands-down the best choice.
- Commercial products outside the cloud provider are good as long as there is a possibility to self-host the solution. The catch is to ensure both SDKs and the runtime are open-source to avoid vendor-lock related surprises in the future.
- For sophisticated projects having language-specific tools and SDKs is a must. It’s always possible to expose internal API endpoints for unsupported languages, but it returns us to working on the tool vs using the tool itself.
Here at AgileVision we use Temporal self-hosted both for internal projects and for SaaS development for our customers and outcomes are pretty good. As it’s obvious from the blog post title, I’ll be talking about pros and cons of Temporal further.
Temporal Basic Concepts
Official documentation does a great job in explaining all ins and outs of Temporal. My goal here to provide a general understanding of basic concepts to understand what’s going to happen in the next sections.
There are four main pillars of Temporal: workflow, activity, worker, and task queue.
As it’s obvious from it’s name, workflow is a code representation of repeatable set of actions. Workflow code in temporal is called “Workflow definition”. Result of the workflow code is “Workflow execution”. It’s important to understand the durability of Temporal workflow is achieved by the mechanism of replays. It means, if the workflow execution is for some reason stopped (e.g. the server was redeployed), Temporal will attempt to execute the workflow code again. Each temporal API call within the workflow produces a command. This command is compared to the event history of the workflow. Replay happens until the last present event is found in the history.
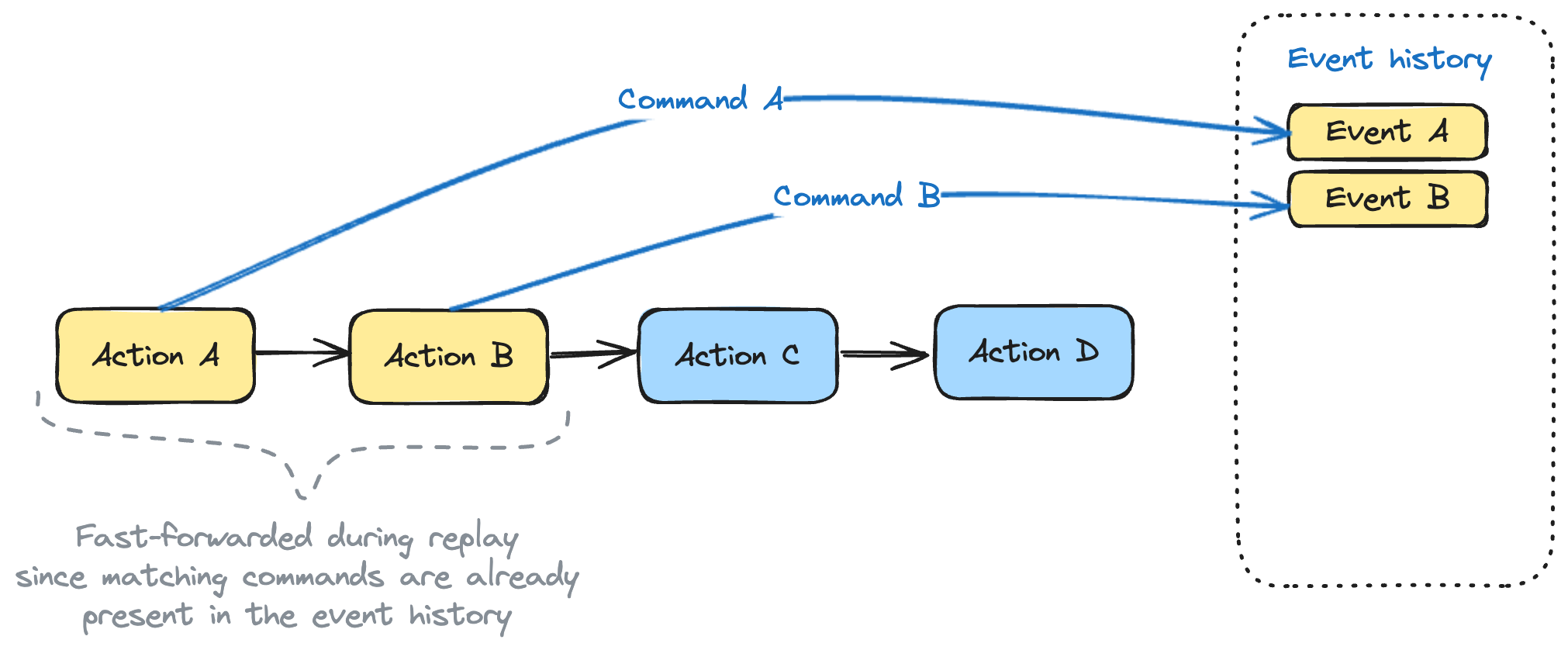 Actions, event history, and commands
Actions, event history, and commands
To be “replayable”, Temporal workflows must be deterministic. In other words, launching workflow with the same input parameters should result in exactly the same set of commands. This means, workflow definition can’t contain non-deterministic code, unless it’s declared inside a side effect.
Activities are predefined actions which occur when the workflow is being executed. As opposite to workflows, activities are not required to be deterministic, though the recommendation is to ensure activity code is idempotent.
Idempotence means the operation has the same result disregarding the number of times it’s being applied. For example, let’s consider such pseudo-code:
def process_order(user_info, order_items): capture_payment(user_info, order_items.total) update_inventory(order_items) send_confirmation_email(user_info, order_items)Let’s imagine the user was able to click the “Place order” button twice for some reason. With this pseudo-code, the payment may be be captured twice, inventory will be decreased twice and the user will get two email notifications. This is definitely not the outcome both the user and the platform developer expects for the ordering workflow.
Furthermore, Temporal activities have “At Least Once” guarantee with retries configured and “No more than once” guarantee with retries disabled. In situations, when the activity started working and completed some job, but the communication between the activity and temporal server interrupted, activities can be considered as not yet executed. This may result in duplicate activity execution upon replay.
For sure, we need to do something about it. The solution is to have idempotency key - an identifier which we can use to determine whether some particular operation was already done. Let’s rewrite our pseudo-code as follows:
def process_order(user_info, order_items, order_id): if order_is_not_processed(order_id) try: mark_as_processing(order_id) capture_payment(user_info, order_items.total) update_inventory(order_items) send_confirmation_email(user_info, order_items) except: mark_as_not_processed(order_id) finally: mark_as_completed(order_id)Now if the call happens twice, subsequent order processing requests will be ignored. The only problem with the code above, it’s not resilient, since failure after marking the order as processing and before exception/final block would mean we end up in an inconsistent state (the order is marked as processing, but we don’t know what was actually done and what failed). So subsequent automatic retries of this code won’t heal the workflow.
Let’s think about possible improvement. Let’s try adding a TTL for the “processing” state, e.g. by storing it in a key-value database with a TTL support:
def process_order(user_info, order_items, order_id): if order_is_not_processed(order_id) try: mark_as_processing(order_id, ttl=MAX_PROCESSING_TIME) capture_payment(user_info, order_items.total) update_inventory(order_items) send_confirmation_email(user_info, order_items) except: mark_as_not_processed(order_id) finally: mark_as_completed(order_id)We fixed the possible inconsistent state, but if you take a look carefully we reintroduced risk of capturing payments, updating inventory and sending emails twice. Let’s further improve the code:
def process_order(user_info, order_items, order_id): if order_is_not_processed(order_id) try: mark_as_processing(order_id, ttl=MAX_PROCESSING_TIME) capture_payment(user_info, order_items.total, order_id) update_inventory(order_items, order_id) send_confirmation_email(user_info, order_items, order_id) except: mark_as_not_processed(order_id) finally: mark_as_completed(order_id)Now since each step accepts our idempotency key, internally these methods can implement the same approach as the order processing flow. Of course, it may not be fully possible due to side effects triggered in those methods. In general, the smaller the chunk of work which needs to be done, the easier to make it idempotent.
Now finally we got a piece of mind and everything looks good. Except for the fact, the moment we decide to generate the idempotency key may determine whether it’s possible to get into a race condition where different idempotency keys are generated for the same action. Let’s assume order_id is generated on the client (to further reduce possible duplicated) and is based on the timestamp:
def generate_order_id(): return f'order-{str(time.time_ns())[:10]}'In a case if the order ID generation is called twice, e.g. on a button click, we are getting different idempotency keys for the same data and end up in the nasty situation again. The solution is to generate the idempotency key way before performing any operations with it, to reduce chances of a race condition during the key generation.
To sum it up, we can play this game forever due the distributed nature of many modern systems and eventual consistency. This is the challenge many e-Commerce and B2B applications are facing every day, and there are many approaches and recommendations on solving. This topic is too wide for a blog post and is part of a broader problem of transactions and ACID. Let’s stop right here, and continue with our topic.
Workers are processes which are responsible for getting tasks from tasks queues and either execute workflows or actions. So in general there are two types of workers - workflow workers and activity workers.
Task queues are polled by worker entities for worker or activity tasks.
Be sure to understand this about Temporal
First of all, temporal cluster is not executing your application code and workflows. It’s responsible for storing workflow states, passing data to/from workflows and activities and also storing the event history.
Activities can reside on different instances, different environments and used within the same workflow. This can be used to strategically leverage strong sides of particular environment to do some heavy lifting. For example, we are working on an Java-based application which involves computer vision capabilities. Core logic is implemented in Java, and everything computer-vision related happens on the Python side by using OpenCV library. Our main workflow then uses activities both from Java and Python in a simple and predictable manner.
Hint: Untyped activities can be used when you need to achieve loose coupling between components. Using untyped activity stubs increases complexity and readability of workflow code though.
Event history size is limited and event payload size directly affects overall Temporal-based applicaton performance, since workflow and activity payloads have to be transferred during the workflow execution. Always evaluate the size of the payload and whether it makes sense to pass identifiers of objects in the DB or object storage instead of passing actual data back and forth.
Temporal production setup is multi-node, fault-tolerant and requires a persistence layer. Be sure to understand required resources and resulting costs for self-hosted setups, since production is not about simply running a temporal CLI.
Temporal has it’s learning curve, which is not that steep, but requires time and attention to understand it. This includes applying temporal in multi-tenant applications, handling side-effects in workflows and leveraging signals. Be sure to read the official documentation and check the community, it worth the investment.
Demonstration
Here is a simple example we use in our NoGaps product to process unstructured PDF documents and turn them into uniform actionable format with comparison possibilities.
@Overridepublic InformationProfileReferenceModel enrich(InformationProfileReferenceModel input) { enrichmentActivities.waitForObjectUpload(input); enrichmentActivities.convertPdfToUnstructuredText(input); enrichmentActivities.createTextVersion(input); enrichmentActivities.enrichDataWithBedrock(input); enrichmentActivities.enrichTags(input); enrichmentActivities.setStateToReady(input);
return input;}This is a multi-step process which uses a generated idempotency key inside the “input” parameter. Each activity is idempotent and is configured with a certain number of retries. In fact, retries are configured in a way it allows us to simply have only a happy-path logic and failures are handled on the Temporal side!
Let’s see an example of activity responsible for waiting until the object upload happened:
public void waitForObjectUpload(InformationProfileReferenceModel reference) { final Optional<InformationProfile> informationProfileOptional = informationProfileRepository .findById(reference.getInformationProfileId());
if (informationProfileOptional.isPresent()) { final InformationProfile informationProfile = informationProfileOptional.get(); final S3Waiter waiter = S3Waiter.builder() .client(s3Client) .build();
final WaiterResponse<HeadObjectResponse> response = waiter.waitUntilObjectExists(o -> o.bucket(informationProfile.getSourceDocument().getBucket()) .key(informationProfile.getSourceDocument().getKey()), o -> { o.maxAttempts(30) .waitTimeout(Duration.ofSeconds(5)) .backoffStrategy(FixedDelayBackoffStrategy.create(Duration.ofSeconds(10))); }); if (response.matched().response().isEmpty()) { throw new IllegalStateException("PDF document is not available"); } } else { throw new IllegalStateException("No information profile is present with the given id: " + reference.getInformationProfileId()); }}This is a very simple action which is used to pause the workflow until the object appears in the object storage. It’s idempotent by nature (no writes are performed) and can’t be safely retried.
Wrapping up
I hope this introductory blog post made you interested in Temporal and gave you some understanding of basic concepts. Now it makes sense to take a deep dive into the official documentation and learn more about this powerful tool.
Need a sharper technical direction?
Bring the bottleneck, the workflow problem, or the modernization question. We will tell you what to do next.
Book a discovery call


